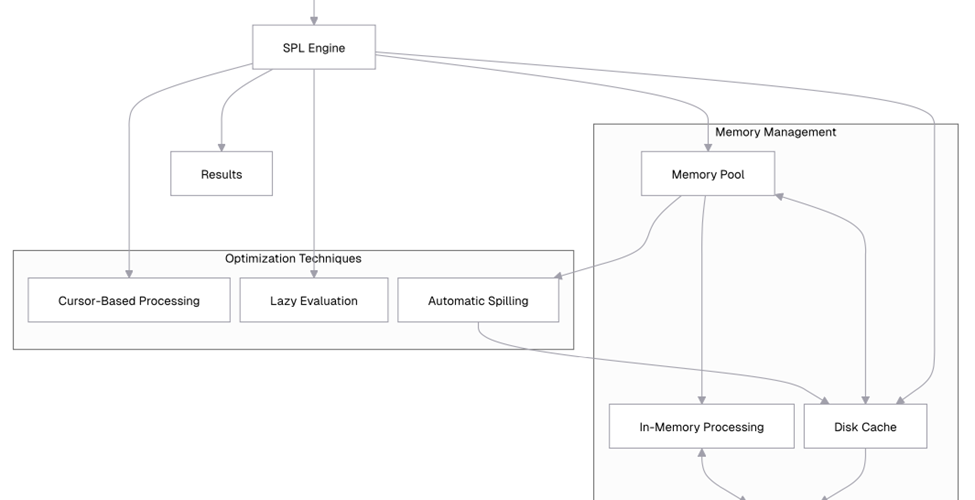
As data volumes continue to grow exponentially, the ability to efficiently process and analyze large datasets has become a critical skill for data professionals. In this article, part of the ‘Moving from Python to esProc SPL’ series, learn how to tackle one of the most challenging aspects of data analysis: handling datasets that are too large to fit into memory.
Traditional data processing tools often struggle when faced with datasets that exceed available RAM. Python’s Pandas, for instance, loads entire datasets into memory, which can lead to performance issues or even crashes when working with gigabytes or terabytes of data.