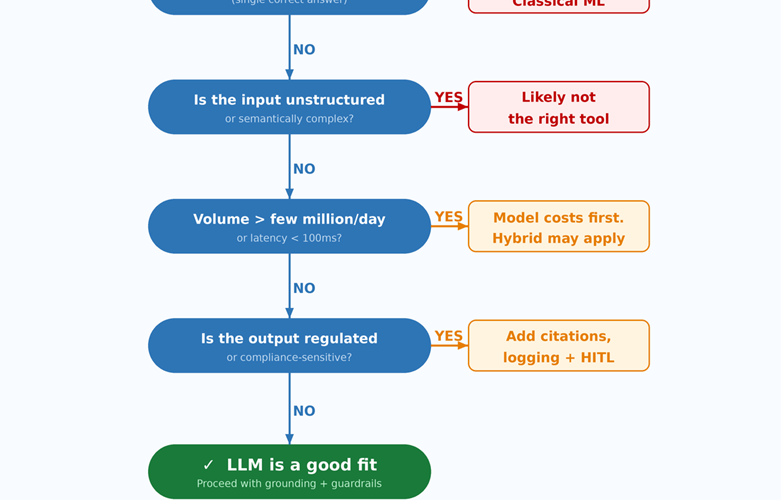
“Let’s add LLMs to the pipeline” has become a familiar refrain in modern data teams, but turning that idea into production reality is where things often go wrong. While large language models can unlock powerful capabilities, they’re just as likely to introduce unnecessary cost, latency, and complexity when misapplied. Drawing on real-world experience building large-scale ML systems, this guide breaks down exactly where LLMs belong in your data pipeline and, just as importantly, where they don’t.
Someone on your team just got back from a conference. Or maybe they spent 20 minutes on LinkedIn. Either way, the message lands in