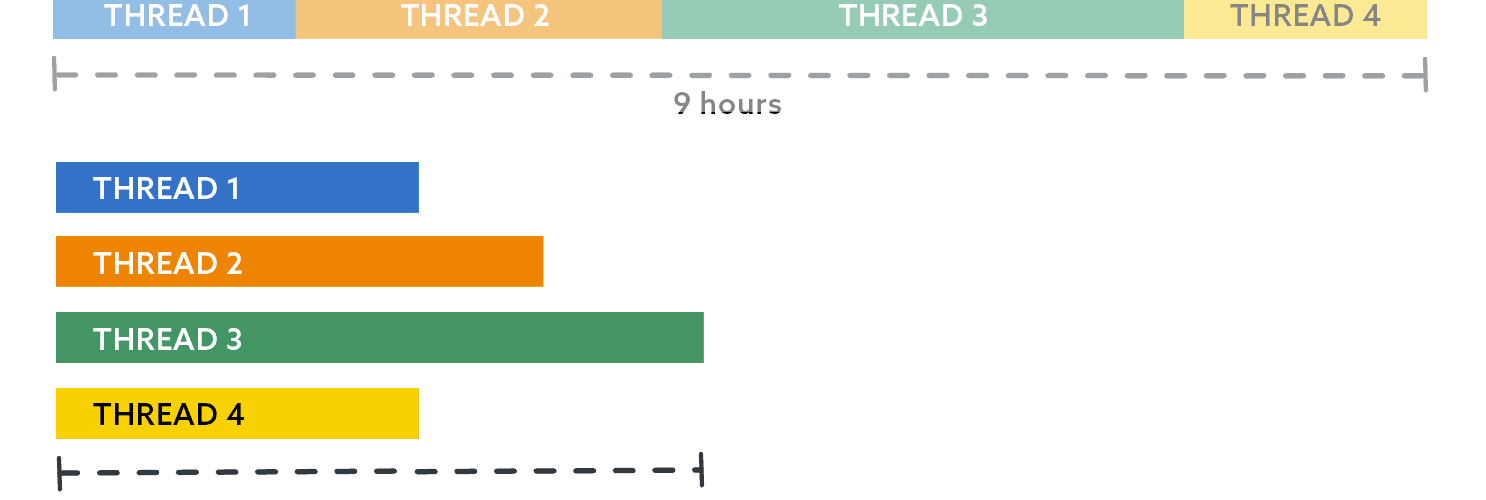
In part 2 of this series, I showed an example implementation of distributing a long-running workload in parallel, in order to finish faster. In reality, though, this involves more than just restoring databases. And I have significant skew to deal with: one database that is many times larger than all the rest and has a higher growth rate. So, even though I had spread out my 9-hour job with 400 databases to run faster by having four threads with 100 databases each, one of the threads still took 5 hours, while the others all finished within 1.5 hours.