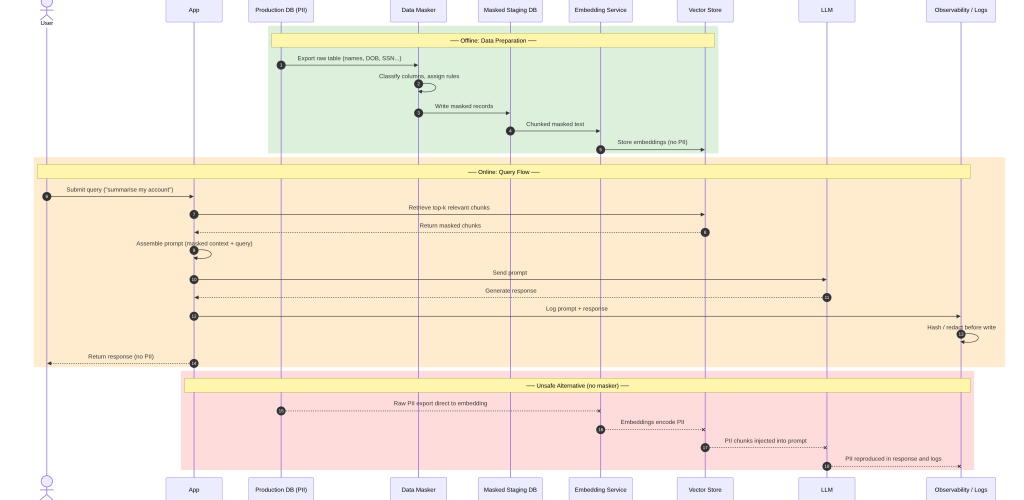
Large language models (LLMs) and the agents built on top of them ingest everything they are given, including personally-identifiable information (PII). In workflows where PII is inevitable, proper measures should exist for data sanitization.
Data can leak through model outputs, embeddings or even logs. Given that you have to use LLMs in your pipeline, in this article I will cover the anonymization techniques you can utilize in an LLM flow to minimize PII exposure vectors.
Before we get started – in case you are undecided on whether to include an LLM or not, this article is a good read to