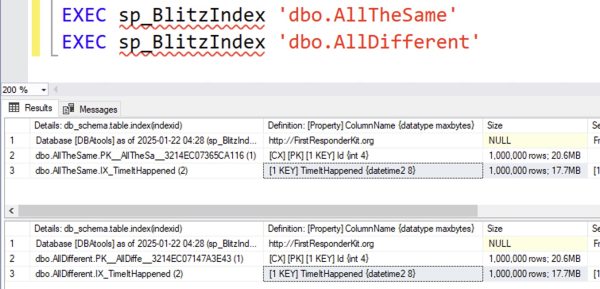
Let’s get a little nerdy and look at database internals. Create two tables: one with a million unique values, and one with a million identical values:
DROP TABLE IF EXISTS dbo.AllTheSame; DROP TABLE IF EXISTS dbo.AllDifferent; CREATE TABLE dbo.AllTheSame (Id INT IDENTITY(1,1) PRIMARY KEY CLUSTERED, TimeItHappened DATETIME2 INDEX IX_TimeItHappened); CREATE TABLE dbo.AllDifferent (Id INT IDENTITY(1,1) PRIMARY KEY CLUSTERED, TimeItHappened DATETIME2 INDEX IX_TimeItHappened); INSERT INTO dbo.AllTheSame (TimeItHappened) SELECT GETDATE() FROM generate_series(1,1000000); INSERT INTO dbo.AllDifferent (TimeItHappened) SELECT DATEADD(ss, value, GETDATE()) FROM generate_series(1,1000000);
I’m just using dates here, not strings, numbers, or other values – those are great experiments for you to play